Paper Information
- Title : PURS: Personalized Unexpected Recommender System for Improving User Statisfaction
- Authors : Pan Li et al.
- Conference : RecSys’20
- URL : 논문 링크
1. Introduction
최근 고전적인 협업 필터링(Collaborative filtering) 알고리즘은 종종 over-specialization, filter bubbles 및 user boredom 문제를 야기한다. 이로 인해 사용자들은 비슷한 아이템을 짧은 기간동안 반복적으로 추천받으면 실증을 낼 수 있다. 이러한 문제를 해결하기 위해여 연구자들은 새롭고(novel), 놀랍고(surprising) 만족스러운(satisfying) 추천을 제공하는 것을 목적으로 하는 추천 모델에 unexpectedness metric을 통합하였다.
-
diversity : 추천하는 아이템 간의 분산만 측정
-
unexpectedness : 사용자의 기대(expectations)에서 추천 아이템의 편차를 측정 -> 사용자의 놀라움(surprise)의 개념을 찾아내고 추천 시스템은 filter bubble에서 벗어날 수 있다
본 논문에선는 추천(recommendations)에 unexpectedness을 통합하는 Personalized Unexpected Recommender System (PURS)를 제안한다.
먼저 모델을 설명하기 전에 본 논문에서 Unexpectedness을 어떻게 정의하는지 간단하게 소개한다.
2. Unexpectedness
2.1 Modeling of Unexpectedness
Latent space에서 과거에 소비한 아이템의 클러스러와 새로운 아이템 사이의 유클리드 거리로 Unexpectedness을 계산한다.
하지만, 대부분의 사용자들은 하나의 관심사(interest)가 아닌 다양한 관심사를 가지고 있으므로 1개의 클러스터가 아닌 여러개의 클러스터를 생성한다.
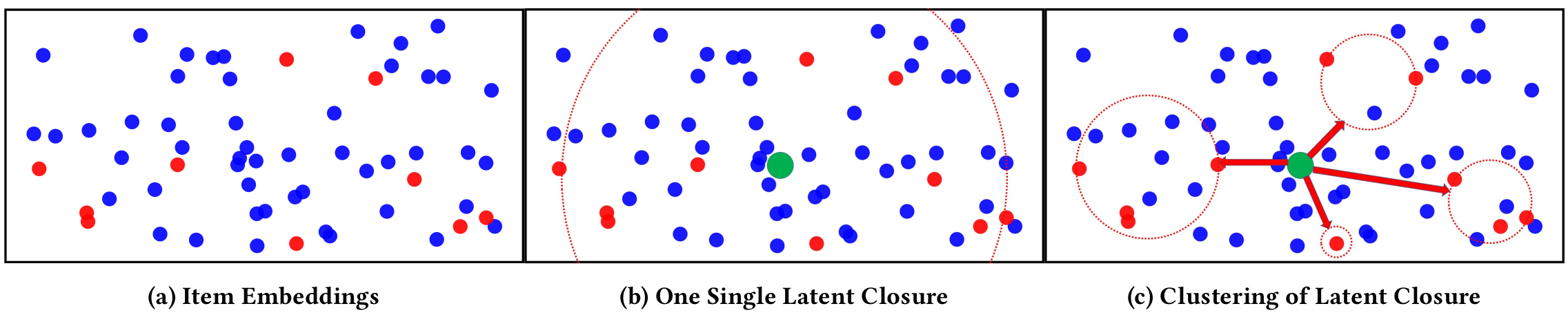
그림 (a)에서 적색 원은 사용자가 이미 소비한 아이템이고, 청색 원은 아직 소비하지 않은 아이템이다. 그림 (b)와 (c)에서의 초록색 점은 사용자에게 추천 할 아이템이다. 그림 (b)처럼 1개의 클러스터만 구성하는 경우에는 클러스터(expected set)에 의도하지 않은 아이템이 포함될 수 있다. 그림 (c)와 같이 여러개의 클러스터를 생성하면, 클러스터 간의 패턴을 식별하고 그에 따라서 expectation sets을 모델링하는 것이 더 쉽다.
본 논문에서는 여러 개의 클러스터를 생성하기 위해서 Mean Shift algorithm을 사용한다.
- Mean Shift algorithm은 비지도 클러스터링 알고리즘이므로 클러스터 수를 지정할 필요가 없다.
- Mean Shift algorithm은 Recommendation applications을 위한 복잡한 multi-modal feature space의 분석에 강력하다.
Mean Shift Algorithm
Mean Shift Algorithm은 클러스터의 중심을 데이터의 밀도가 높은 곳으로 이동시킨다. 데이터의 밀도를 추정하기 위해서 KDE(Kernel Density Estimation)을 사용한다. 초기 추정치를 $x_i$, 관측치를 $x$라 두고 다음과 같은 커널 함수를 사용한다.
\[K(x_i - x) = e^{-c \parallel x_i - x \parallel ^2}\]$K$에 의해서 결정된 window의 밀도의 가중 평균은 다음과 같이 계산된다.
\[m(x) = \frac{\sum_{x_i \in N(x)} K(x_i - x) x_i}{\sum_{x_i \in N(x)} K(x_i - x)}\]- $N(x)$ : $x$의 이웃(neighborhood)
Mean Shift algorithm은 $x$를 $m(x)$로 초기화하고, $m(x)$가 수렴할 때까지 추정 과정을 반복한다.
각 사용자 $u$에 대해서 과거 행동 sequence을 ${ i_1, i_2, \cdot\cdot\cdot i_n}$으로 추출하고, latent space에서 해당 임베딩을 ${w_1, w_2, \cdot\cdot\cdot, w_n}$으로 추출한다. 그런 다음 Mean Shift algorithm을 적용하여 사용자 관심(interest) 클러스터 ${ C_1, C_2, \cdot\cdot\cdot, C_N}$을 생성한다.
각 사용자 $u$와 각의 새로운 추천 아이템 $i_\star$에 대한 unexpectedness은 각 클러스터 $C_k$ 사이의 가중 평균 거리와 새 아이템 $w_\star$의 임베딩으로 모델링된다.
\[unexp_{i_*, u} = \sum_{k=1}^N d(w_*, C_k) \times \frac{\mid C_k \mid}{\sum_{k=1}^N \mid C_k \mid}\]다음으로 본 논문에서 사용하는 Unexpected Activation Function에 대해서 설명한다.
2.2 Unexpected Activation Function
Unexpected activation function $f(\cdot)$가 다음과 같은 수학적 성질을 만족해야 한다고 제안한다:
- Continuity
- Boundedness
- Unimodality
- Short-Tailed
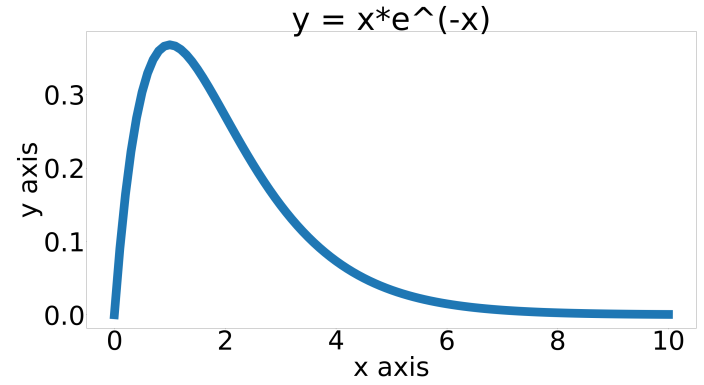
본 논문에서는 4가지 조건을 만족하는 많은 함수 후보들 중에서, $f(x) = x * e^{-x}$ 를 unexpected activation function으로 사용한다.
3. Personalized Unexpected Recommender System
3.1 Overview
\[Utility_{u,i} = r_{u,i} + f(unexp_{u,i}) * unexp.factor_{u,i}\]-
$r_{u,i}$
feature 및 과거 행동을 바탕으로 아이템 $i$에 대한 사용자 $u$의 CTR 추정
-
$unexp_{u,i}$
사용자 $u$에 대한 아이템 $i$의 unexceptedness
-
$unexp.factor_{u,i}$
아이템 $i$에 대한 사용자 $u$의 unexpectedness에 대한 개인화(personalized) 및 session-based perception(인식)
-
$f(\cdot)$
unexpectedness에 대한 activation function
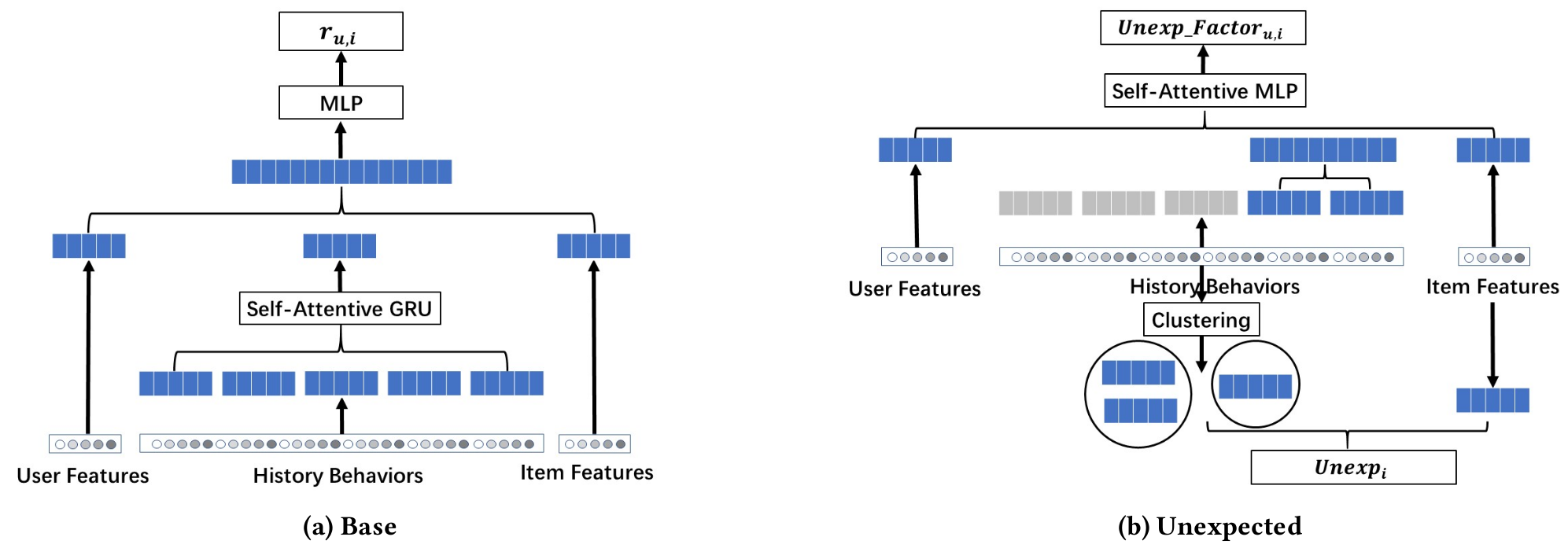
-
Base model
특정한 사용자-아이템 쌍의 CTR을 추정하는 모델
-
Unexpected model
새로운 추천의 unexpectedness와 예상하지 못한 것(unexpectedness)에 대한 사용자의 인식(perception)을 찾아내는 모델
3.2 User and Item Embeddings
사용자의 관심을 효과적으로 식별하고 해당하는 아이템을 추천하려면, 사용자 및 아이템에 대한 feature-level information을 찾아내는 것이 중요하다. 사용자 및 아이템의 고유한 특성이 추천의 성공 여부를 결정하는 중요한 역할을 한다.
사용자 및 아이템 정보를 latent space에 임베딩 형태으로 찾아내는 딥러닝 기반의 오토 인코더 방법을 사용한다. 사용자 $u$와 아이템 $i$에 대한 명시적 특성(explicit feature)을 각각 $W_u = [w_{u_1}, w_{u_2}, \cdot\cdot\cdot, w_{u_m}]$ 및 $W_i = [w_{i_1}, w_{i_2}, \cdot\cdot\cdot, w_{i_n}]$로 표시한다. 여기서, $m$과 $n$은 사용자 및 아이템 특성 벡터(feature vector)의 차원을 나타낸다.
오토 인코더은 feature vector을 latent embedding으로 매핑하는 인코더 네트워크와 latent embedding에서 feature vector을 복원하는 디코더 네트워크라는 두 개의 개별 신경망을 훈련한다. 본 논문에서는 인코더와 디코더를 모두 MLP(Multi-layer perceptron)으로 구성하였다. MLP는 다음과 같은 loss $L$을 사용해서 representations을 학습한다:
\[L = \parallel W_u - MLP_{dec}^u (MLP_{enc}^u (W_u)) \parallel\] \[L = \parallel W_i - MLP_{dec}^i (MLP_{enc}^i (W_i)) \parallel\]3.3 Click-Through-Rate Estimation ($r_{u,i}$) using Self-Attentive GRU
특정한 추천 아이템 $i$에 대해, 우리의 목표는 사용자 $u$가 이 추천을 클릭할 것인지 여부를 예측하는 것이다. 이는 아이템 $i$의 content와 사용자 $u$의 interest 간의 일치에 크게 의존한다. 즉, 과거 행동에서 사용자의 선호도를 정확하게 추론하는 것이 중요하다.
사용자 $u$의 과거 소비를 시퀀스 $P_u = [i_{u_i}, i_{u_2}, \cdot\cdot\cdot, i_{u_K}]$로 나타낸다. click-through-rate 예측 모델은 user behavior sequence $P_u$에 대해 모든 임베딩 벡터를 풀링함으로서 고정된 길이의 user interest의 representation vector을 얻는다.
본 논문에서는 시퀀스 임베딩을 얻기 위하여 bidirectional GRU neural network을 활용한다.
훈련을 위해서 먼저, behavior sequence을 이전 단계에서 얻은 해당하는 아이템 임베딩에 매핑한다. GRU 학습 과정을 설명하기 위해, update gate와 reset gate에 대한 현재 정보 및 과거 정보의 weight matrices을 각각 $W_z$, $W_r$, $U_z$, $U_r$로 표시한다. 그러면 timestep $t$에서 hidden state은 다음 식을 얻을 수 있다.
\[z_t = \sigma_g (W_z x_t + U_z h_{t-1} + b_z)\] \[r_t = \sigma_g (W_r x_t + U_r h_{t-1} + b_r)\] \[h_t = (1 - z_t) \circ h_{t-1} + z_t \circ \sigma_h (W_h x_t + U_h (r_t \circ h_{t-1}) + b_h)\]- $x_t$ : timestep $t$에서 behavior embedding input
- $h_t$ : output user interest vector
- $z_t$ : update gate의 상태
- $r_t$ : reset gate의 상태
과거의 소비에 따라서 현재의 추천에는 다른 영향을 미칠 수 있다. 따라서, behavior sequence의 item-level geterogeneity을 찾아내기 위해 시퀀스 모델링 동안 self-attentive mechanism을 통합한다. 일반적으로 각 출력 요소 $s_t$는 선형 변환된 입력 요소의 가중치 합으로 계산된다.
\[s_t = \sum_{i=1}^n \alpha_{ti} (x_i W^t)\]각 가중치 계수 $\alpha_{ti}$는 소프트맥스 함수를 사용해서 계산된다.
\[\alpha_{ti} = \frac{\exp e_{ti}}{\sum_{i=1}^n \exp e_{ti}}\]- $e_{ti}$ : 입력 요소 $x_t$와 $x_i$를 비교하는 compatibility function을 사용하여 계산된다.
모든 timestep에 걸쳐서 hidden step를 반복적으로 계산하여, 마지막 behavior sequence에서 final hidden state을 얻는다. 이는 사용자의 과거 행동에 대한 latent semantic 정보를 찾아내는 user interest embeddings $R_u$을 구성한다. CTR 추정을 위해, user interest embedding $R_u$를 사용자 임베딩 $E_u$ 및 아이템 임베딩 $E_i$와 연결하여 MLP 네트워크에 입력으로 사용한다. $r_{u,i} = MLP(R_u ; E_u ; E_i)$
3.4 Unexpected Factor ($unexp.factor_{u,i}$) using Self-Attentive MLP
사람들마다 unexpectedness recommendations에 대해서 선호도가 다를 수 있으므로, unexpectedness에 대한 인식은 session-based information에 영향을 받는다. 따라서 $unexp.factor_{u,i}$를 계산할 때 사용자의 과거 행동을 고려하고 personalized session-based recommdations을 제공해야 한다.
사용자 $u$의 과거 소비를 sequence $P_u = [i_{u_1}, i_{u_2}, \cdot\cdot\cdot, i_{u_K}]$로 나타내며, unexpectedness을 식별하기 위해 전체 시퀀스가 아닌 특정 window 길이 $K$를 지정한다.
Window에서 가장 최근의 사용자 행동이 추출되어 MLP 네트워크의 입력으로 사용된다. current unexpected recommendations에 대한 추출된 historic behavior의 heterogeneity을 찾아내기 위해서, 각 아이템의 임베딩이 네트워크에 공급되는지 여부를 결정하기 위해서 local activation unit의 구조를 활용한다. 네트워크 구조의 변경 없이 사용자의 다양한 관심을 표현하는 대신, local activation unit은 현재 추천 후보에 대한 과거 행동의 관련성을 적응적으로 계산할 수 있다.
특히, local activation unit은 weighted sum pooling을 수행하여 각 행동(behavior) 임베딩의 activation stage을 계산하고 하나의 표현(representation)을 생성한다. 사용자 $u$에 대한 아이템 임베딩 시퀀스를 $P_u = [E_{i_1}, E_{i_2}, \cdot\cdot\cdot, E_{i_K}]$로 표시한다. 사용자 $u$와 아이템 $i$에 대한 unexpected factor $unexp.factor_{u,i}$은 다음과 같이 계산된다:
\[unexp.factor_{u,i} = MLP(E_u; \sum_{j=1}^K a(E_u, E_{i_j}, E_i)E_{i_j};E_i)\]- $a(\cdot)$ : 과거 구매에 대한 activation weight로 출력을 갖는 feed-forward network이다.
4. Experiments
모델의 하이퍼 파라미터는 베이지안 최적화를 통해 최적화된다.
- K : 10
- Learning rate : 1
- Exponential decay : 0.1
- Optimizer : SGD
- Embedding 차원 : 32
- MLP의 layer : 32 x 64 x 1
- batch size : 32
4.1 Data
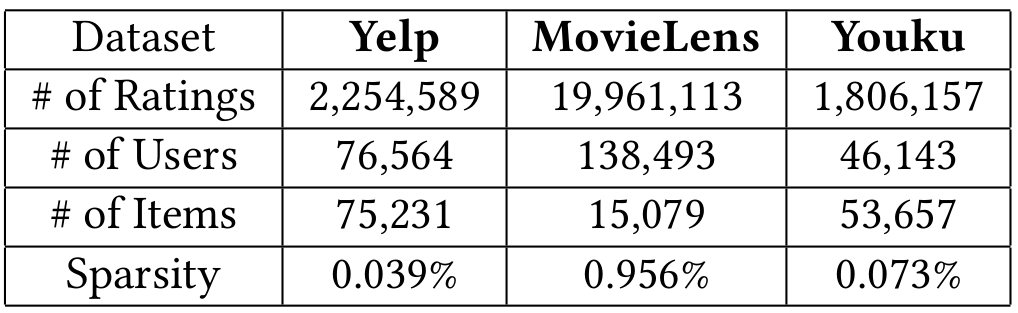
- Yelp와 MovieLens 데이터셋의 경우에는 Rating 정보이므로 3.5를 기준으로 click & non-click으로 변환한다.
4.2 Baselines and Evaluation Metrics
PURS가 unexpected와 useful recommendations을 동시에 제공한다는 것을 보여주기 위해 두 그룹의 SOTA baselines을 선택한다.
- Click-through-rate prediction models
-
DIN (Deep Interest Network)
특정 아이템에 대한 과거 행동으로부터 user interests의 representation을 적응적으로 학습하기 위해 local activation unit을 설계
-
DeepFM
추천을 위해 Factorization machines의 power와 feature learning을 위해 deep learning을 결합한 새로운 신경망 구조
-
Wide & Deep
수동으로 설계된 cross product features을 다루기 위해서 wide 모델을 활용하고 features 간의 비선형 관계를 추출하기 위해서 deep 모델을 활용한다.
-
PNN (Product-based Neural Network)
feature extractor을 제공하기 위해서 추가적인 product layer을 도입한다.
- Unexpected recommendations models
-
SPR (Serendipitous Personalized Ranking)
AUC 최적화에서 item popularity를 고려하여 기존의 personalized ranking methods을 확장한다.
-
Auralist
accuracy, diversity, novelty 및 serendipity이라는 원하는 목표 사이의 균형을 동시에 유지하는 personalized recommendation system
-
DPP (Determinantal Point Process)
Relevant 및 diverse 추천을 생성하기 위해 fast greedy MAP inference 접근 방식을 사용한다.
-
HOM-LIN
Hybrid utility function을 통해 추천을 제공하는 SOTA unexpected recommendation algorithm
평가 과정을 위해서는 다음과 같은 accuracy 및 novelty metrics을 선택한다.
-
AUC : predictted CTR로 모든 아이템의 순위를 매기고 클릭 정보와 비교하여 추천 순서의 goodness을 측정
-
HR@10 : 상위 10개 추천의 클릭 수
-
Unexpectedness : consideration sets에 포함되지 않고 추천 시스템에서 기대하는 것과는 다른 사용자에 대한 추천을 측정 (식 3 참고).
-
Coverage : 데이터셋의 모든 개별 아이템에 대한 추천의 고유 아이템 비율
5. Results
5.1 Recommendation Performance
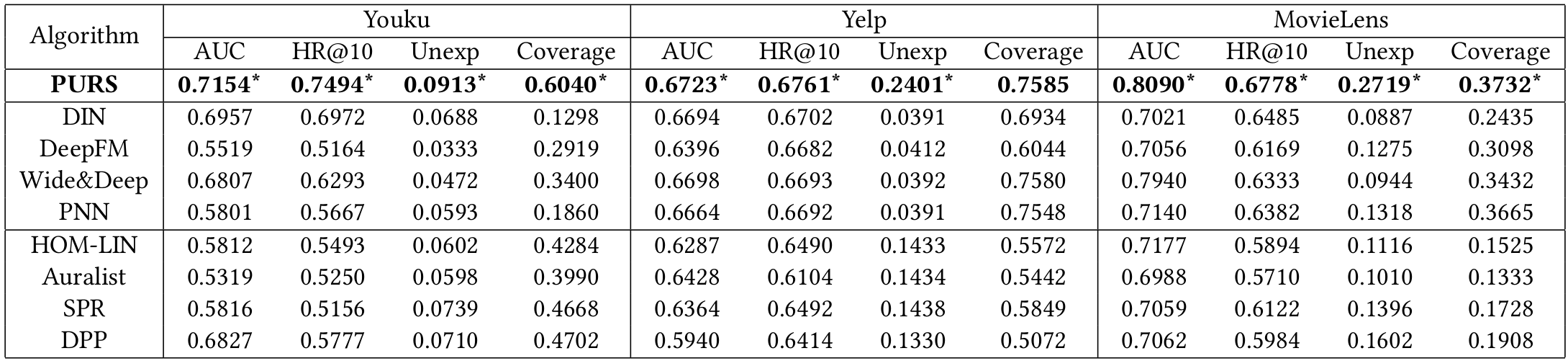
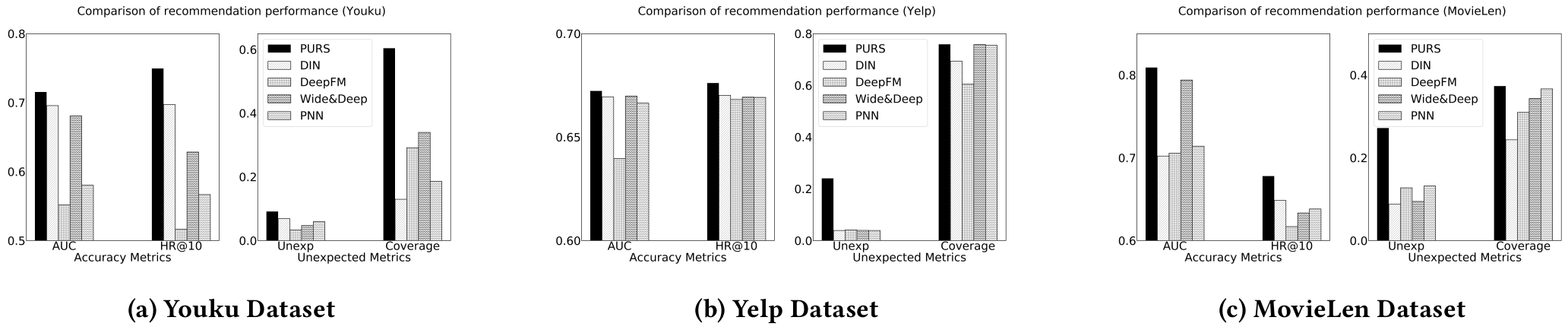
실험 결과 모든 성능 지표에서 제안하는 PURS가 우수함을 보인다.
5.2 Ablation Study
PURS은 다음 4가지 요소를 추천 모델에 통합한 결과이다.
-
Unexpectedness
참신하고(Novel) 만족스러운(Satisfying) 추천을 제공하는 것을 목표로 함
-
Unexpected Activation Function
Utility function에 unexpectedness의 입력을 조정
-
Personalized and Session-Based Factor
unexpectedness에 대한 인식의 사용자 및 session-level heterogeneity을 포착
-
Clustering of Behavior Sequence
다양한 user interest를 추출하고 user expectations을 구성
각 요소의 중요성을 보여주기 위한 실험을 진행하기 위해서, 제안된 모델을 다음과 같은 변형 모델과 비교한다.
-
PURS-Variation 1 (Gaussian Activation)
원래의 모델에서 unexpected activation function로 가우시안 분포을 사용한다.
$Utility_{u,i} = b_u + b_i + r_{u,i} + exp(-unexp_{u,i}^2) * unexp.factor_{u,i}$
-
PURS-Variation 2 (No Activation)
원래의 모델에서 unexpected activation function을 제거한다.
$Utility_{u,i} = b_u + b_i + r_{u,i} + unexp_{u,i} * unexp.factor_{u,i}$
-
PURS-Variation 3 (No Unexpectedness Factor)
원래의 모델에서 unexpectedness factor을 제거한다.
$Utility_{u,i} = b_u + b_i + r_{u,i} + f(unexp_{u,i})$
-
PURS-Variation 4 (No Unexpectedness)
원래의 모델에서 unexpectedness을 제거한다.
$Utility_{u,i} = b_u + b_i + r_{u,i}$
-
PURS-Variation 5 (Single Closure of User Interest)
원래의 모델과 동일한 Utility function을 사용하지만, $unexp_{i_, u} = d(w_, C_u)$로서 클러스터링 절차에 대한 unexpectedness을 제거한다. 즉, $C_u$는 사용자 $u$에 대한 모든 과거 상호적용에 의해 생성된 전체 latent closure이다.

PURS와 변형 모델들의 성능을 비교하여 unexpected recommendations의 기여에 4가지 구성요소의 통합에서 비롯됨을 보인다.
5.3 Improving Accuracy and Novelty Simultaneously
CTR 예측을 위한 모델은 unexpected recommendations model보다 정확도 측정값은 높지만 unexpected에 대한 성능은 낮은 모습을 보이며, 그 반대 또한 마찬가지이다. 즉, 정확성과 unexpected는 트레이드 오프 관계를 보인다. 하지만, PURS은 다음과 같이 훈련과정에서 AUC와 Unexpectedness metrics에 대해서 동시에 개선할 수 있다.
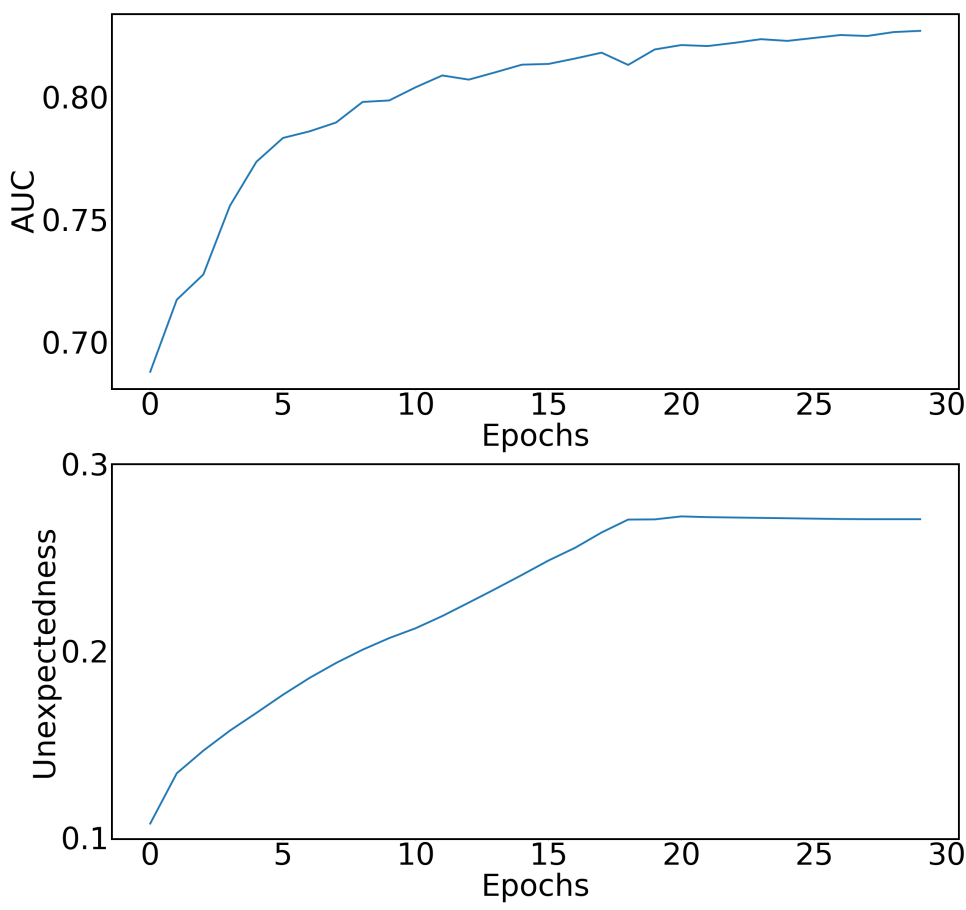
5.4 Scalbility
확장성(Scalbility)을 테스트하기 위해 데이터의 크기가 100개에서 1,000,000개로 증가하는 경우에 대해 PURS을 사용한다.
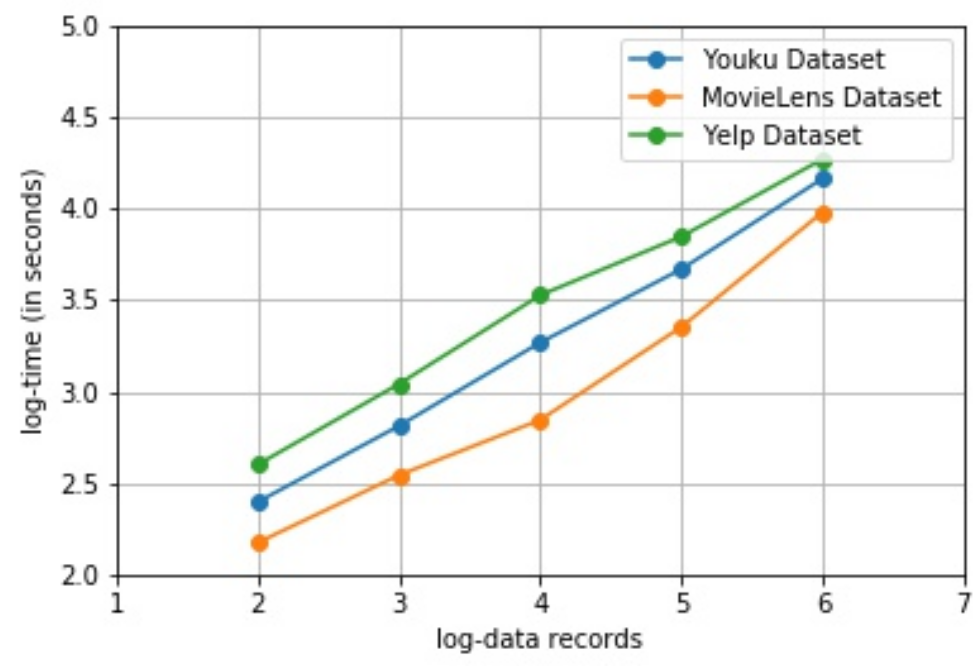
위의 그림처럼, 데이터의 크기가 증가할 수록 시간 또한 선형적으로 증가한다. PURS는 네트워크 파라미터를 효율적으로 학습할 수 있으며 실제로도 잘 확장된다.
6. Online A/B Test
동영상 추천 플랫폼인 Alibaba-Youku에서 2019년 11월부터 2019년 12월까지 온라인 A/B 테스트를 실시한다. 사용되는 성능지표는 다음과 같다.
- VV (Video View) : 각 사용자의 평균 시청 횟수
- TS (Time Spent) : 각 사용자가 플랫폼에서 보낸 평균 시간
- ID (Impression Depth) : 한 세션 동안의 평균 인상(감명)
- CTR (Click-Through Rate) : 사용자가 추천 비디어를 클릭하는 비율
추가로 Unexpectedness와 Coverage도 측정한다.

PURS을 사용하는 경우 모든 성능 지표에서 유의미한 개선을 보여준다.